import pandas as pd
DataFrame : 2D Array of Indexed Data

df.set_index('Day')
- Day를 index로 지정

df[ a : b ]
- lavel 기준, [ a, b ) row table return
df[ a ]
- label기준, a row information return
df.loc[ a : b ]
- label 기준, [ a, b ] row table return
df.iloc[ a : b ]
- row 순서 기준, [ a, b ) row table return

Add a new row / Delete an existing row
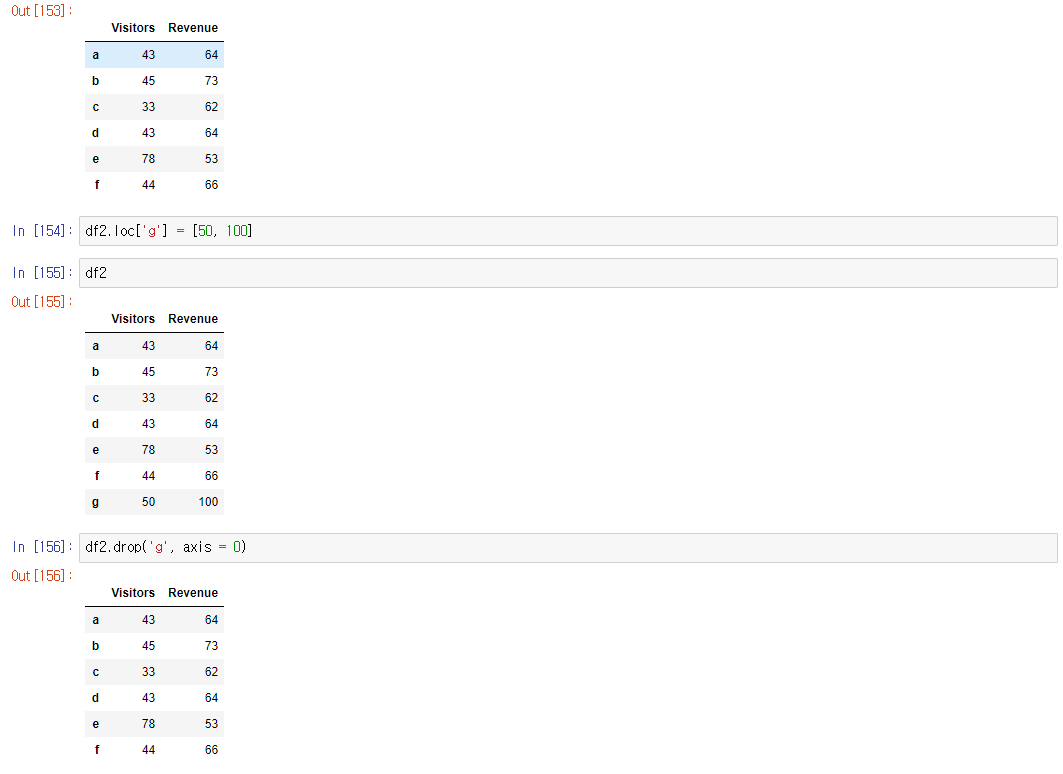
pd.DataFrame(df2, columns = ['Revenue', 'Visitor'])
- column 순서 변경

Nan으로 이뤄진 new column 생성 / del df2['Debt'] or pd2.drop('Debt', axis = 1)는 column 삭제
- new column 생성 후 copy & return 필요. row는 필요없는데 column은 필요함. 왜 그런지는 모르겠음..

df.rename(columns = type(dict), index = type(dict))
- list도 가능함. dict를 쓰면 1:1 matching해서 변경이 가능

df.iterrows( )
- index / row를 순차적으로 접근 가능함

df2[df2['Revenue'] > 65].count( )
df2['Revenue'].mean( )
df2.cov( ) , max( ), min( ) ...
df2.describe( )
- 기초통계량
- numeric data에 대해서만 출력함
- df2.num_data.describe( ) 처럼 특정 column에 대해서만 출력도 가능함
- df2.describe( include = 'all' ) : numeric data 외에 다른 값도 확인 가능
- df2.describe( include = 'category' ) : categorical column 값을 확인 가능
df.count( ) = df.count(axis = 0) = df.count(axis = 'rows')
- ↓방향으로 count / column 별 계산
df.count(axis = 1) = df.count(axis = 'columns')
- → 방향으로 count / row 별 계산
df.max( ) = df.max(axis = 0)
- ↓ 방향으로 max return
- dtype : object 나오는 경우..? , int64, float64
df.max( ) = df.max(axis = 1)
- → 방향으로 min return
grouped = df.groupby( 'Column_name' ) , df.groupby( ['column_name1', 'column_name2'] )
- return 값은 register or 해당 df의 정보임. 실제 값을 return하지 않음.
- grouped.mean( ) , grouped.sum( ) 등 numeric data 출력으로 통계치 활용가능
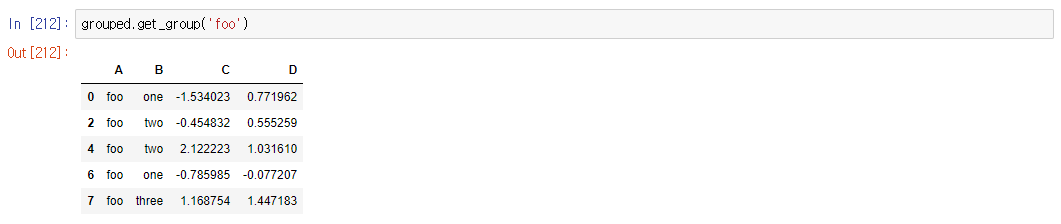
- grouped.get_group(' column data ')

merge( ) & join( )
- heterogeneous table들의 결합 (schema가 다른 table들)
- merge( ) : various optional parameters
- pd.merge( a_data, b_data, on = 'key' or ['key1', 'key2'] , how = 'inner' or 'outer', indecator = True)
: on = 'attr' 로 merge함, 없으면 동일 attr. name 기준으로 merge
: indicator = merge method 알려줌(left_only, right_only, both)
- join( ) : simpler than merge( )
: join( )은 merti column merge 지원 안함.
- a_data.set_index('key').join(b_data.set_index('key')
- a_data.join(b_data, on = 'key' , how = 'inner' or 'outer')
: on = a_data의 'key' column기준으로 join, how = default는 index기준 left outer join
- df.head( n = 5 (default) ) : index 상위 5개 return
concat( ) & append( )
- homogeneous table들의 결합 (schema가 같은 table들)
- Nan에 의존해서 heterogeneous에도 concat( ) 사용 가능
- concat( ) : various Optional Parameters
- pd.concat( [df1, df2, df3] , axis = 0 (default) , ignore_index = True, keys = ['x', 'y', z'])
: ignore_index = True : index 재구성 (default = False) )
: keys = 새로운 index 추가부여, result.loc['y'] 로 filtering가능 /
dic type으로 넣는것도 가능{'x' : df1, 'y' : df2, 'z' : df3} (pd.concat( add_index ))
- pd.concat( [df1, pd.DataFrame(dicts)], ignore_index = True, sort = True )
- append( ) : simpler than concat( )
- df1.append( [df2, df3] , ignore_index = True )
- df1.append(dicts, ignore_index = True, sort = True )
'공부는 언제까지 해야 하나' 카테고리의 다른 글
| [Python] pandas module - File IO (0) | 2021.02.04 |
|---|---|
| [Python] pandas module - Time Series Data (0) | 2021.02.04 |
| [Python] pandas module - Series object (0) | 2021.02.03 |
| [Python] numpy module - File IO (0) | 2021.02.03 |
| [Python] numpy module - matrix operation (0) | 2021.02.03 |

